Desarrollamos soluciones que permitan que las máquinas aprendan y puedan facilitar tareas rutinarias o pronosticar situaciones antes de que ocurran.
¿Qué es el Machine Learning?
El aprendizaje automático se define como una agrupación de algoritmos que pueden aprender de datos archivados y realizar predicciones a partir de ellos modificando de manera importante la forma de trabajo tradicional.
El Machine Learning es una disciplina del campo de la IA (Inteligencia Artificial), que crea sistemas que identifican patrones a partir de millones de datos para procesar predicciones. Gracias a los algoritmos que aprende el sistema, toma decisiones autónomas sin intervención humana.

Diferencia entre Inteligencia Artificial,
Machine Learning & Deep Learning.

La IA (Inteligencia Artificial), es la capacidad de las computadoras y/o sistemas informáticos de mostrar un comportamiento “inteligente”, en la mayoría de los casos predictivos con base a datos históricos obtenidos.
Mientras que el Machine Learning, es una de técnica que se utiliza para crear y mejorar dicho comportamiento. Esto mediante entrenamientos automáticos basados en la exposición a datos, de esta forma se pretende que el computador aprenda por si solo.
El Deep Learning, es una forma de Machine Learning que entrena a un sistema para que aprenda por sí mismo, a través del reconocimiento de patrones, realizando tareas como los seres humanos. El Deep Learning utiliza una clase específica de algoritmos, llamados redes neuronales.
Proyectos con Machine Learning
Clasificador de imágenes
En este proyecto se implementaron varios algoritmos de aprendizaje supervisado, comenzando con el K vecinos más cercanos o K-nearest neighbors (KNN) este algoritmo se basa en medir la proximidad para determinar a que grupo pertenece un elemento en específico. Su mayor uso se da cuando se busca clasificar.


El siguiente es el K-means, es un algoritmo de clasificación no supervisado que agrupa elementos basándose en sus características. Dicha agrupación se basa en minimizar las distancias entre cada elemento y el centroide de cada grupo.
Y por último SVM (Support-vector machine) o máquina de vectores de soporte, la clasificación por medio de este algoritmo funciona mediante la correlación de datos a un espacio de características, de esta manera los puntos de datos pueden ser categorizados. Mediante esta categorización se puede establecer una separación entre las categorías, transformando los datos de manera que el separador se puede extraer como hiperplano. Así, las características de nuevos datos son utilizados para acercarse al grupo al que pueden pertenecer.


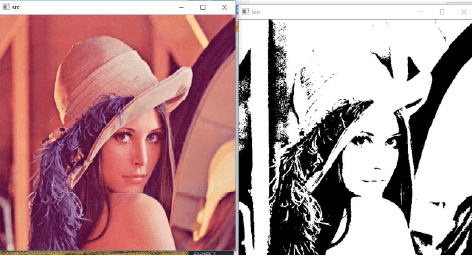

En el proceso de clasificación también se tienen que procesar las imágenes de manera que puedan ser clasificadas de una mejor manera, para este proceso de imágenes se tomaron en cuenta, la escala de grises, binarización y ecualización de histogramas.
La escala de grises convierte los pixeles de una imagen a una escala de tonalidades que están entre el blanco y negro.
En la binarización primero se convierte una imagen a color a escala de grises, luego cada uno de los pixeles se les da un valor de 0(negro) o 255(blanco) condicionando si dicho pixel esta o no por encima de cierto valor, en general un punto medio entre ambos extremos (0-255).
En el proceso de la ecualización de histogramas se busca un ajuste en las intensidades de la imagen para que el contraste pueda ser mejor y tener una vista mas clara.
Extracción de datos
HOG
Mediante este método de extracción de datos se busca obtener características mediante el cálculo y contabilización del histograma de la dirección del gradiente del área local de la imagen.
CANNY
A través de la reducción de ruido y encontrar la intensidad del gradiente se busca destacar los bordes de la imagen para que pueda ser más fácil su clasificación.
SIFT
A diferencia de los dos anteriores métodos, SFIT destaca puntos característicos una imagen, estos puntos deben ser invariantes y distintivos de la imagen.
Durante la ejecución de la aplicación se puede observar las diferentes opciones y combinaciones que se pueden hacer, tanto en procesamiento de imágenes como en extracción de datos.
